 “三个模型”的协作绩效增长了30%。 Sakana AI提出了一种新的推理扩展算法,以显着提高模型之间的协作性能
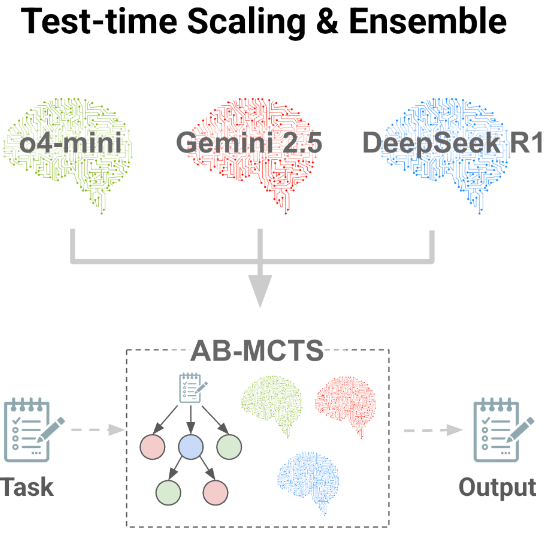
资料来源:DeepTech Deep Technology“三个鹅卵石,Zhyge Liang”。这种谚语不仅适用于人类,而且适用于大型模型。 7月1日,日本的Sakana AI由Transformer八八人组成的Llion Jones共同创建了一种新的推理方法,称为Adaptive Branch的Monte Carlo搜索树木。 (来源:Sakana AI)这种新的推理时间尺度算法允许通过允许多个最新一代模型(例如Gemini 2.5 Pro,O4-Mini,DeepSeek-R1-0528)来达到集体智能。研究小组认为,最大的成就来自于人类集体智慧的启发的思想冲突,同样的原则适用于AI。诸如Chatgpt,Gemini和Deepseek之类的模型非常精致,每个模型都有自己独特的Advan培训的胜利和偏见,研究小组认为它们也是解决集体问题的宝贵资源。 AB-MCT可以使用这些特征来解决单个AI系统难以解决的复杂问题,因为多个模型可以共同工作以有效地测试和错误。在参考点ARC-AGI-2上,AB-MCT结合了前卫AI模型,例如O4-Mini,Gemini-2.5-Pro和DeepSeek-R1-0528,以创建一个称为Multi-LLLM AB-MCT的系统,发现系统性能超过了独特模型的性能。图| AB-AGI-2结果报告(来源:Sakana AI)在AB-MCT和Multi-LLM AB-MCT上表明,该研究基于该团队在2024年进行的进化模型合并的工作。但是,在这项研究中,我们表明“相信Hyhybrid Action” A a a a a'hive a“ hive”。我们将专注于更改“使用盖子” AI。团队认为,未来的AI系统可以共同努力解决复杂的挑战,例如人类专家并克服单个模型的局限性。搜索软件以获取推理扩展。推理?搜索的双重维度是多少?当人类面临无法立即解决的问题时,他们会做什么?最有可能的方法是花更多的时间思考自己,尝试犯错或与他人一起工作。那么,您可以以相同的方式解决问题吗?今天已知关注的一个例子是推理时间的延长(或试用时间的延长)。该范式表明,对于单个复杂问题,推理可以提高性能时会分配更多的计算机资源。长期以来,训练过程中的性能与计算复杂性之间的关系(即训练时间增加),但研究人员了解到,在模型完成培训后,性能与使用计算预算之间存在正相关。这些方法之一是使用加固学习产生更长的思维链。这大大改善了推理模型的功能,例如OpenAI和DeepSeek的R1。实际上,这也与人类发现问题时采用的“更多思想”的策略相对应。除了给推理模型提供更多的“思考时间”外,您还可以通过反复查看问题,甚至在必要时从头开始来优化答案。图|推理时间扩展报告的三个地址(来源:Sakana AI)使用测试和错误方法,用于大型模型,因此使用一种称为“顺序优化”的深搜索方法。该方法使用大型模型来生成答案并进行迭代优化。另一种方法是重复采样。也就是说,一个大型模型基于相同的通知几次生成解决方案。重复采样开始反复咨询大型模型,但没有利用先前的尝试的结果,即大型MO的随机性dels(也就是说,对同一问题产生不同的答案)。尽管重复抽样方法似乎效率低下,但先前的报告表明,在许多参考点,它比连续优化要好。 (来源:sakana ai)然后,如果它是详细的搜索(即现有解决方案的优化)或广泛的搜索(即新解决方案的生成),它表明它已帮助使用了更大的模型来找到更好的答案。但是,以前没有办法将它们结合起来。如果初始尝试不正确,则可能很难通过重复优化解决方案的步骤优化方法找到正确的答案。重复采样方法的使用,也就是说,反复提出相同的问题,永远不会提高潜力,而是不完整的解决方案。因此,研究人员认为,您可以重复同样的问题以获得更好的初始取向,或者如果您可以实现近距离的人类测试过程和错误以优化潜在的解决方案,然后可以重复相同的问题。根据这个想法,研究团队开发了AB-MCT。这允许在深度和范围内进行灵活的搜索,并适应解决的问题和上下文。在CTS的情况下,使用AB-M,当模型发现有希望的解决方案时,可以考虑到新解决方案的生成,可以连续优化。与现有方法相比,这使您可以获得更好地调用相同数量的较大模型的响应。因此,从本质上讲,AB-MCT是一种新的,更有效的推理形式。 (来源:Sakana AI)为了实现以前的灵活搜索,AB-MCTS扩展了Carloeso Mount Carloeso树的方法很大。具体而言,在每个节点中,AB-MCT使用概率模型来评估这两个操作的潜在质量。生成全新的操作或优化和改善现有解决方案。从这些模型中提取质量评估数据,以确定NE的地址XT步骤。一个重要的挑战是如何评估尚未生成的新解决方案的质量。为此,AB-MCT评估了混合模型和概率分布的使用,实现了真正的灵活搜索并有效地解决了上述问题。为了完全利用AI合作的多个大型模型的集体智能优势,该团队开发了一个AB-MCT多LLLM系统,该系统不仅允许自适应搜索地址,而且还允许基于特定问题和情况的最佳大型模型的动态选择。除了为AB-MCT(更广泛)生成新的解决方案(更广泛)并优化现有的解决方案外,AB-MCTS还添加了新步骤以选择最大的使用模型。图|多LLM AB-MCT的搜索算法的一般描述(来源:Sakana AI)用于此方法,您应该知道哪些较大的模型更有效。但是,这个我S最初未知,因此必须在搜索过程中调整系统。这意味着使用各种大型模型从一开始就可以很好地平衡,重点是显示出解决问题的方法。实际上,这可以认为是多臂插槽计算机的问题(即自动学习领域的经典问题)。但是,解决了标准多个插槽问题的每个条目。先前问题的关键是适应了动态上更改的条目,并且输入内容本身取决于系统产生的响应。从选择大型模型的角度来看,研究人员将单个概率模型分配给每种类型的大型模型,并采用了类似于上述AB-MCTS方法的汤普森采样方法。这些概率模型是根据每个伟大模型在搜索过程中的工作方式进行更新的,这导致了更大的潜力,这是因为较大的模型是S当选。在调查过程中,研究小组基于ARC-AGI-2参考测试首次发布了多LLM AB-MCT。系统的初步实验结果。抽象和推理的语料库(ARC-AGI)旨在评估可以推断和解决全新问题的灵活人类智能。因此,Arc-Agi在Mradientional评估的性质上有所不同,该性质证明了该测试的特定技能或知识。尽管对于人类而言,ARC-AGI-1一直是一项简单但困难的研究任务,但研究团队在其实验中使用了最具挑战性的ARC-AG-2,并在ARC-AGI-2公共评估集中进行了120个任务进行了实验。图|实验的ARC-AGI-2样本问题(来源:Sakana AI)是建立搜索迭代或最大数量的大调,并指示模型以Python代码形式生成转换规则。此搜索过程的起始机制基于k艾尔奖励指标。根据生成的Python代码正确解决的演示案例数量。为了首先评估搜索算法的最大潜在性能,研究人员使用了Pass@k Metric。这用于测量在K中找到至少一个正确的解决方案。这与官方的ARC-AGI-2竞赛标准不同。这通常使用@2标准。通过@2方法需要附加步骤。换句话说,为搜索结果选择潜在的候选者。在这项研究中,研究人员致力于通过Pass@k评估“搜索”功能。图| ARC-AGI-2中的AB-MCT和AB-MCT多LLM的结果显示了Pass@250的成功率(来源:Sakana AI)。实际上,当研究人员使用O4-Mini进行重复采样时,成功解决了23%的问题,完全证明了重复采样的强大功能,远远超出了测试的得分。但是,拟议的AB-MCT提高了分数额外的27.5%。特别是在LE之后大约50年代的出色模型,两种方法之间的差异变得更加明显。图| ARC-AGI-2的TheAB-MCT和多LLM AB-MCT结果表明,@K取决于对大型模型的调用数量(来源:Sakana AI),最终通过利用最新一代模型作为集体智能和多LLLM AB-MCT和Multi-LLM AB-MCT找到了足够的解决方案。有趣的是,研究人员发现,但是DeepSeek-R1-0528本身并不是特别好,但是当与多LLLM AB-MCT结合使用时,它可以有效地增加溶剂能力的数量。多LLM AB-MCTS研究团队发现的一个关键功能是,这些模型可以动态分配合格的特定问题的合格程度。下图清楚地说明了这种行为。根据特定的大规模模型观察到对多LLM AB-MCT的明确偏好,具体取决于示范示例中成功率较高的情况。发生这种情况之所以发生,是因为该算法标识了在搜索过程中对特定问题更有效的大型模型,并增加了使用模型的频率。图|大型模型量表用于在Pass@250条件下使用多个LLM AB-MCT解决ARC-AGI-2的各种任务(来源:Sakana AI),此外,研究团队还发现,组合多个大型模型可以解决无法通过单个大型模型解决的问题。不仅为每个问题分配了最佳的大型模型。在一个示例中,最初由O4-Mini生成的解决方案不正确,但是DeepSeek-R1-0528和Gemini-2.5-Pro将其用作轨道,可以在下一步中找到正确的解决方案。这表明多LMAB-MCTS系统可以解决过去无法解决前卫模型无法解决的问题。如上所述,Eresearch资格的主要方法是评估搜索功能,因此采用了通行证@k metric.hizo。作为参考参考,当研究人员使用基于规则的方法(即,选择高参考高奖励代码搜索)时,多LMAB-MCTS系统通过过滤两个最终响应时,获得了2个19.2%的得分。 Pass@2的结果已经很棒,但是与30%的Pass@k指标相比,差距超过10%。因此,研究小组认为,可以通过开发选择最终响应并建立更复杂的奖励模型或引入更大的模型(例如裁判)来解决更复杂的奖励设计的更复杂模型来解决此问题。通常,该结果表明推断的扩展仍然存在脱位。该方法表明,这些模型的推理过程通过反复执行推理过程并将多个大型模型与独特的个性相结合,甚至可以更大。将来,Sakana ai wil我是基于这项研究的重点,要关注AI和集体智能的演变,并将努力创建更新的AI系统。 See: https://arxiv.org/abs/2503.04412https://x.com/sakanaailabs/status/1939854145856708910Https://github.com/sakanaaai/treequestps://github.com/sakanaai //操作/Absptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptspsss。
“三个模型”的协作绩效增长了30%。 Sakana AI提出了一种新的推理扩展算法,以显着提高模型之间的协作性能
资料来源:DeepTech Deep Technology“三个鹅卵石,Zhyge Liang”。这种谚语不仅适用于人类,而且适用于大型模型。 7月1日,日本的Sakana AI由Transformer八八人组成的Llion Jones共同创建了一种新的推理方法,称为Adaptive Branch的Monte Carlo搜索树木。 (来源:Sakana AI)这种新的推理时间尺度算法允许通过允许多个最新一代模型(例如Gemini 2.5 Pro,O4-Mini,DeepSeek-R1-0528)来达到集体智能。研究小组认为,最大的成就来自于人类集体智慧的启发的思想冲突,同样的原则适用于AI。诸如Chatgpt,Gemini和Deepseek之类的模型非常精致,每个模型都有自己独特的Advan培训的胜利和偏见,研究小组认为它们也是解决集体问题的宝贵资源。 AB-MCT可以使用这些特征来解决单个AI系统难以解决的复杂问题,因为多个模型可以共同工作以有效地测试和错误。在参考点ARC-AGI-2上,AB-MCT结合了前卫AI模型,例如O4-Mini,Gemini-2.5-Pro和DeepSeek-R1-0528,以创建一个称为Multi-LLLM AB-MCT的系统,发现系统性能超过了独特模型的性能。图| AB-AGI-2结果报告(来源:Sakana AI)在AB-MCT和Multi-LLM AB-MCT上表明,该研究基于该团队在2024年进行的进化模型合并的工作。但是,在这项研究中,我们表明“相信Hyhybrid Action” A a a a a'hive a“ hive”。我们将专注于更改“使用盖子” AI。团队认为,未来的AI系统可以共同努力解决复杂的挑战,例如人类专家并克服单个模型的局限性。搜索软件以获取推理扩展。推理?搜索的双重维度是多少?当人类面临无法立即解决的问题时,他们会做什么?最有可能的方法是花更多的时间思考自己,尝试犯错或与他人一起工作。那么,您可以以相同的方式解决问题吗?今天已知关注的一个例子是推理时间的延长(或试用时间的延长)。该范式表明,对于单个复杂问题,推理可以提高性能时会分配更多的计算机资源。长期以来,训练过程中的性能与计算复杂性之间的关系(即训练时间增加),但研究人员了解到,在模型完成培训后,性能与使用计算预算之间存在正相关。这些方法之一是使用加固学习产生更长的思维链。这大大改善了推理模型的功能,例如OpenAI和DeepSeek的R1。实际上,这也与人类发现问题时采用的“更多思想”的策略相对应。除了给推理模型提供更多的“思考时间”外,您还可以通过反复查看问题,甚至在必要时从头开始来优化答案。图|推理时间扩展报告的三个地址(来源:Sakana AI)使用测试和错误方法,用于大型模型,因此使用一种称为“顺序优化”的深搜索方法。该方法使用大型模型来生成答案并进行迭代优化。另一种方法是重复采样。也就是说,一个大型模型基于相同的通知几次生成解决方案。重复采样开始反复咨询大型模型,但没有利用先前的尝试的结果,即大型MO的随机性dels(也就是说,对同一问题产生不同的答案)。尽管重复抽样方法似乎效率低下,但先前的报告表明,在许多参考点,它比连续优化要好。 (来源:sakana ai)然后,如果它是详细的搜索(即现有解决方案的优化)或广泛的搜索(即新解决方案的生成),它表明它已帮助使用了更大的模型来找到更好的答案。但是,以前没有办法将它们结合起来。如果初始尝试不正确,则可能很难通过重复优化解决方案的步骤优化方法找到正确的答案。重复采样方法的使用,也就是说,反复提出相同的问题,永远不会提高潜力,而是不完整的解决方案。因此,研究人员认为,您可以重复同样的问题以获得更好的初始取向,或者如果您可以实现近距离的人类测试过程和错误以优化潜在的解决方案,然后可以重复相同的问题。根据这个想法,研究团队开发了AB-MCT。这允许在深度和范围内进行灵活的搜索,并适应解决的问题和上下文。在CTS的情况下,使用AB-M,当模型发现有希望的解决方案时,可以考虑到新解决方案的生成,可以连续优化。与现有方法相比,这使您可以获得更好地调用相同数量的较大模型的响应。因此,从本质上讲,AB-MCT是一种新的,更有效的推理形式。 (来源:Sakana AI)为了实现以前的灵活搜索,AB-MCTS扩展了Carloeso Mount Carloeso树的方法很大。具体而言,在每个节点中,AB-MCT使用概率模型来评估这两个操作的潜在质量。生成全新的操作或优化和改善现有解决方案。从这些模型中提取质量评估数据,以确定NE的地址XT步骤。一个重要的挑战是如何评估尚未生成的新解决方案的质量。为此,AB-MCT评估了混合模型和概率分布的使用,实现了真正的灵活搜索并有效地解决了上述问题。为了完全利用AI合作的多个大型模型的集体智能优势,该团队开发了一个AB-MCT多LLLM系统,该系统不仅允许自适应搜索地址,而且还允许基于特定问题和情况的最佳大型模型的动态选择。除了为AB-MCT(更广泛)生成新的解决方案(更广泛)并优化现有的解决方案外,AB-MCTS还添加了新步骤以选择最大的使用模型。图|多LLM AB-MCT的搜索算法的一般描述(来源:Sakana AI)用于此方法,您应该知道哪些较大的模型更有效。但是,这个我S最初未知,因此必须在搜索过程中调整系统。这意味着使用各种大型模型从一开始就可以很好地平衡,重点是显示出解决问题的方法。实际上,这可以认为是多臂插槽计算机的问题(即自动学习领域的经典问题)。但是,解决了标准多个插槽问题的每个条目。先前问题的关键是适应了动态上更改的条目,并且输入内容本身取决于系统产生的响应。从选择大型模型的角度来看,研究人员将单个概率模型分配给每种类型的大型模型,并采用了类似于上述AB-MCTS方法的汤普森采样方法。这些概率模型是根据每个伟大模型在搜索过程中的工作方式进行更新的,这导致了更大的潜力,这是因为较大的模型是S当选。在调查过程中,研究小组基于ARC-AGI-2参考测试首次发布了多LLM AB-MCT。系统的初步实验结果。抽象和推理的语料库(ARC-AGI)旨在评估可以推断和解决全新问题的灵活人类智能。因此,Arc-Agi在Mradientional评估的性质上有所不同,该性质证明了该测试的特定技能或知识。尽管对于人类而言,ARC-AGI-1一直是一项简单但困难的研究任务,但研究团队在其实验中使用了最具挑战性的ARC-AG-2,并在ARC-AGI-2公共评估集中进行了120个任务进行了实验。图|实验的ARC-AGI-2样本问题(来源:Sakana AI)是建立搜索迭代或最大数量的大调,并指示模型以Python代码形式生成转换规则。此搜索过程的起始机制基于k艾尔奖励指标。根据生成的Python代码正确解决的演示案例数量。为了首先评估搜索算法的最大潜在性能,研究人员使用了Pass@k Metric。这用于测量在K中找到至少一个正确的解决方案。这与官方的ARC-AGI-2竞赛标准不同。这通常使用@2标准。通过@2方法需要附加步骤。换句话说,为搜索结果选择潜在的候选者。在这项研究中,研究人员致力于通过Pass@k评估“搜索”功能。图| ARC-AGI-2中的AB-MCT和AB-MCT多LLM的结果显示了Pass@250的成功率(来源:Sakana AI)。实际上,当研究人员使用O4-Mini进行重复采样时,成功解决了23%的问题,完全证明了重复采样的强大功能,远远超出了测试的得分。但是,拟议的AB-MCT提高了分数额外的27.5%。特别是在LE之后大约50年代的出色模型,两种方法之间的差异变得更加明显。图| ARC-AGI-2的TheAB-MCT和多LLM AB-MCT结果表明,@K取决于对大型模型的调用数量(来源:Sakana AI),最终通过利用最新一代模型作为集体智能和多LLLM AB-MCT和Multi-LLM AB-MCT找到了足够的解决方案。有趣的是,研究人员发现,但是DeepSeek-R1-0528本身并不是特别好,但是当与多LLLM AB-MCT结合使用时,它可以有效地增加溶剂能力的数量。多LLM AB-MCTS研究团队发现的一个关键功能是,这些模型可以动态分配合格的特定问题的合格程度。下图清楚地说明了这种行为。根据特定的大规模模型观察到对多LLM AB-MCT的明确偏好,具体取决于示范示例中成功率较高的情况。发生这种情况之所以发生,是因为该算法标识了在搜索过程中对特定问题更有效的大型模型,并增加了使用模型的频率。图|大型模型量表用于在Pass@250条件下使用多个LLM AB-MCT解决ARC-AGI-2的各种任务(来源:Sakana AI),此外,研究团队还发现,组合多个大型模型可以解决无法通过单个大型模型解决的问题。不仅为每个问题分配了最佳的大型模型。在一个示例中,最初由O4-Mini生成的解决方案不正确,但是DeepSeek-R1-0528和Gemini-2.5-Pro将其用作轨道,可以在下一步中找到正确的解决方案。这表明多LMAB-MCTS系统可以解决过去无法解决前卫模型无法解决的问题。如上所述,Eresearch资格的主要方法是评估搜索功能,因此采用了通行证@k metric.hizo。作为参考参考,当研究人员使用基于规则的方法(即,选择高参考高奖励代码搜索)时,多LMAB-MCTS系统通过过滤两个最终响应时,获得了2个19.2%的得分。 Pass@2的结果已经很棒,但是与30%的Pass@k指标相比,差距超过10%。因此,研究小组认为,可以通过开发选择最终响应并建立更复杂的奖励模型或引入更大的模型(例如裁判)来解决更复杂的奖励设计的更复杂模型来解决此问题。通常,该结果表明推断的扩展仍然存在脱位。该方法表明,这些模型的推理过程通过反复执行推理过程并将多个大型模型与独特的个性相结合,甚至可以更大。将来,Sakana ai wil我是基于这项研究的重点,要关注AI和集体智能的演变,并将努力创建更新的AI系统。 See: https://arxiv.org/abs/2503.04412https://x.com/sakanaailabs/status/1939854145856708910Https://github.com/sakanaaai/treequestps://github.com/sakanaai //操作/Absptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptsptspsss。